Lokale KI-Modelle werden viel diskutiert, weil sie einige Vorteile gegenüber den KI-Modellen in der Cloud haben.

Aus den folgenden Gründen sind solche Modelle eine ernsthafte Alternative, insbesondere für Nutzer, denen Datenschutz, Firmengeheimnisse und die DSGVO wichtig sind:
- Die bearbeiteten Daten verlassen den Rechner nicht.
Das ist insbesondere wichtig, wenn man mit personenbezogenen Daten arbeitet, insb. mit Kundendaten. Die DSGVO ist hier sehr eindeutig: man kann nicht einfach die Daten von Kunden, Mitarbeitern oder Geschäftspartnern in eine Cloud KI wie ChatGPT, Gemini oder Claude hochladen. Die einzige Ausnahme ist, wenn man einen Auftragsdatenverarbeitungsvertrag hat, der allerdings insb. in den kleinen Privatkundentarifen nicht angeboten werden. - Man hat die komplette Kontrolle über das KI-Modell.
Wir alle erinnern uns an das Drama, das durch das Internet zog, als OpenAI das Modell ChatGPT 4o von einem Tag auf den anderen ersetzt hat. Solange das lokale Modell nicht von uns geändert wird, bleibt es auch in 10 Jahren noch so. D.h., dass lokale Workflows stabil laufen und nicht spontan ausfallen können. - Lokale Modelle reichen problemlos für Standard-Aufgaben aus.
Die Use Cases für lokale Modell sind vielfältig, aber im Wesentlichen drehen sie sich um Datenmanipulation, insb. für Fälle, in denen personenbezogene Daten verarbeitet werden sollen. Während lokale Modelle nicht optimal für komplexe Aufgaben geeignet sind und nicht auf so viel Wissen zugreifen können wie Cloud KIs, die wesentlich größer und ressourcenhungriger sind, reichen sie für einfache Aufgaben problemlos aus.
Die nötigen Downloads
Um lokale KI zu nutzen, sind folgende Dinge notwendig:
- Eine lokale KI-Umgebung, in der das Modell läuft.
Ich nutze meistens die kostenlose Open Source Software LM Studio, aber es gibt noch einige andere Alternativen wie GPT4all oder Jan. Diese Software ist die Umgebung, in der das ausgewählte lokale KI-Modell läuft. Die Installation dieser Umgebungen ist so einfach wie die Installation jedes anderen normalen Software-Pakets. In diesem Artikel gehe ich davon aus, dass LM Studio installiert wird. Zum Zeitpunkt dieses Artikels ist die V0.4.2 die aktuelle Version. - Ein lokales KI-Modell.
Auch hier gibt es diverse Angebote, insb. auch von den großen KI-Cloud-Anbietern. Aufgrund der guten Kombination aus Größe, Geschwindigkeit und Ergebnisqualität arbeite ich meistens mit Google Gemma. Die Modelle werden nach der Installation der KI-Umgebung dort ausgewählt und heruntergeladen. Es ist kein separater Download notwendig.
Die Installation der lokalen KI-Umgebung
Die Installation der KI-Umgebung ist sehr einfach. Bei LM Studio lädt man lediglich die Installationsdatei herunter und installiert sie unter Windows wie jede andere Software. Bei Macs muss vermutlich noch akzeptiert werden, dass man eine heruntergeladene Software installieren möchte, aber das habe ich nicht getestet.
Die Installation des KI-Modells
Damit wir eine KI nutzen können, muss nach der Installation der KI-Umgebung LM Studio links der Reiter „Modell Search“ (Strg + Shift + M) ausgewählt werden, um ein Modell zur Installation auszuwählen.
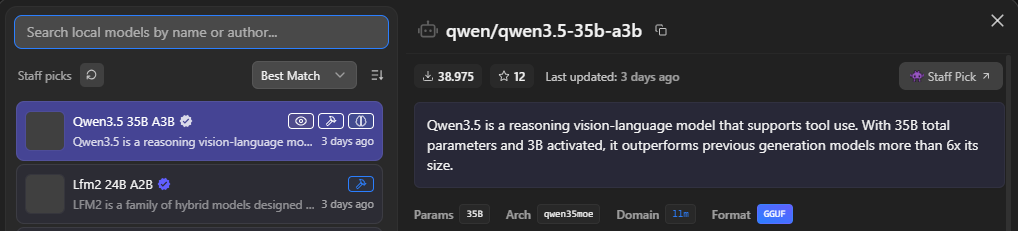
Ich empfehle für schnelle Tests das Modell Gemma-3n-e4b (4,2 GB), da dieses gezielt für Laptops und Mobilgeräte entwickelt wurde und auch auf Mittelklasse-Laptops flüssig läuft. Je besser die Hardware ist auf der die Modelle gestartet werden, desto größer können die Modelle sein. Das aktuelle High End-Open-Source-Modell von Google ist Gemma-3-27b (16,4 GB).
Nach dem Download: Laden des Modells
Im Gegensatz zu den Cloud-KIs kann man bei einer lokalen KI-Umgebung nicht einfach mit einem Klick das Modell wechseln. Auf eigener Hardware dauert es einen Moment, bis ein neues Modell bereit ist, um zu arbeiten.
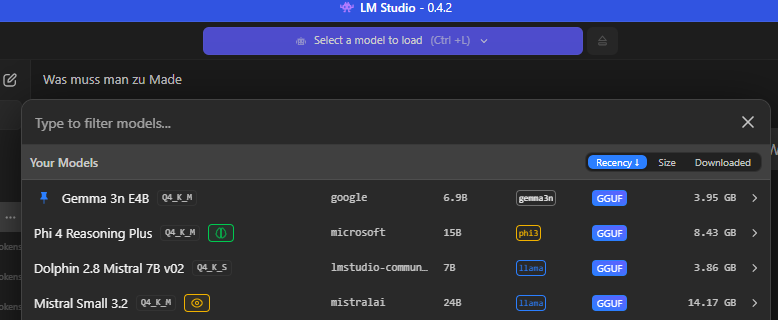
Man wählt das Modell im Chatfenster (Strg + 1) aus:
Nach der Auswahl des Modells kann man noch die Parameter des Modells ändern – ich ändere hier im normalen Einsatz Nichts:
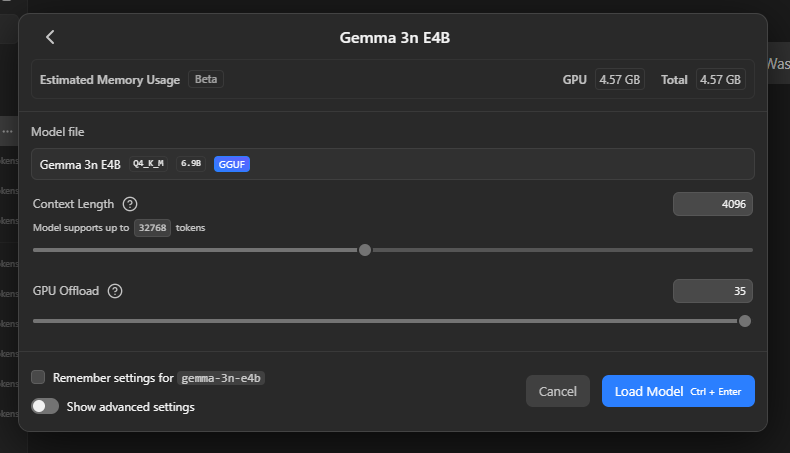
Nachdem man mit dem „Load Model“ Knopf bestätigt hat, wird das Modell geladen – der Fortschritt wird oben im Chatfenster angezeigt.

Los geht’s!
Und damit ist das Modell auch schon einsatzbereit! Auf meiner Mittelklasse-Hardware ist Gemma finde ich bzgl. der Geschwindigkeit völlig akzeptabel:
