Der Hype Train fährt noch: aktuell macht das neue Modell Gemini 3 Pro von Google, das Version 2.5 ablöst, Schlagzeilen bzgl. seiner Leistungsfähigkeit.

Und ja, die Daten sind eindeutig, in den allen Tests schneidet Gemini 3 besser als das frisch erschienene ChatGPT 5.1 ab:
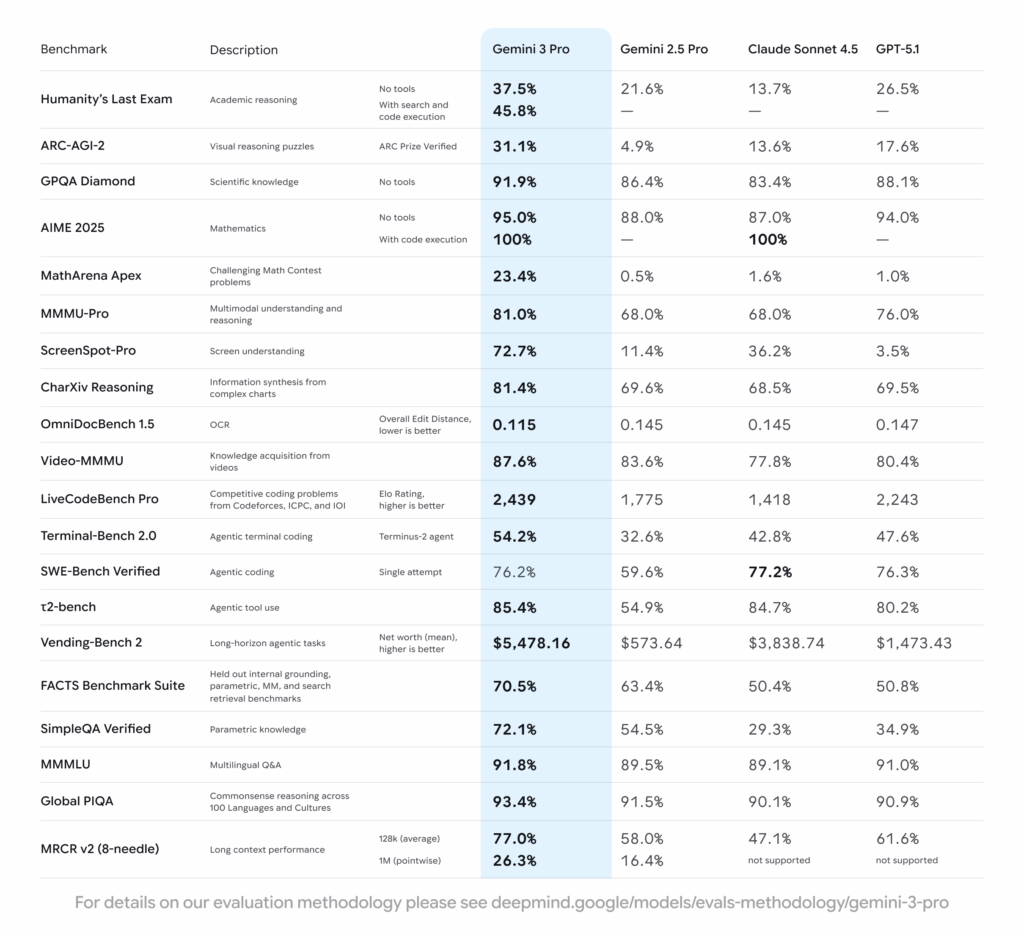
Das sind ganz schön viele, kleingedruckte Zahlen. Wenn man jetzt mal ein paar rausnimmt, die für „normale“ Menschen besonders relevant sein dürften, sehen wir:
- Multimodales Verstehen und Schlußfolgern: 81%
+5% ggü. ChatGPT 5.1, +13% Gemini 2.5 - Mehrsprachige Fragen & Antworten: 91,8%
+ 0,8% ggü. ChatGPT, +2,3% ggü. Gemini 2.5 - Gesunder Menschenverstand: 93,4%
+2,5% ggü. ChatGPT 5.1, +1,9% ggü. Gemini 2.5
Hier frage ich mich, ob das wirklich im Alltag spürbar sein wird – aktuell wirkt Gemini 3 auf mich primär schneller.
Gemini 3: starke Steigerungen der Performance
Bei den Werten mit extremen Steigerungen gibt es zwei, die sicherlich bald spannend werden:
- Bildschirm-Verständnis: 72,7%
+69,2% ggü. ChatGPT 5.1, +61,3% ggü. Gemini 2.5 - Langfristige Agenten-Tätigkeiten: $5.478,16
+271% ggü. ChatGPT 5.1, +854% ggü. Gemini 2.5
Das Bildschirm-Verständnis wird einen starken Unterschied machen, wenn Gemini 3 als aktives Helferlein in Chrome einzieht. Das ist natürlich ein massiver Sprung, der sicher einen Unterschied machen wird, wenn Google sich vermutlich zeitnah ernsthaft mit den KI-Browsern Comet und Atlas anlegt.
Ebenso, und wahrscheinlich damit verknüpft, wird es beim Thema des Jahres, KI-Agenten, einen großen Unterschied machen, dass Gemini 3 hier für langfristige Aufgaben deutlich besser ausgestattet zu sein scheint als die Konkurrenz, wobei Claude Sonnet 4.5 schon eher in einer vergleichbaren Liga mitspielt. Anthropic ist hier aber auch vergleichsweise sehr weit gewesen bisher.
Eher Fortschritte in der Nische?
Die anderen starken Fortschritte scheinen mir eher Nischenthemen zu sein, nicht Dinge, die ein „normaler“ Mensch in der Arbeit mit einem KI-Chatbot braucht:
- Humanity’s Last Exam: 37,5%
+11% ggü. ChatGPT 5.1, +15,9% ggü. Gemini 2.5 - Herausfordernde Mathematik-Probleme: 23,4%
+22,4% ggü. ChatGPT 5.1, +22,9% ggü. Gemini 2.5 - Parametrisches Wissen: 71,1%
+36,2% ggü. ChatGPT 5.1, +16,7 ggü. Gemini 2.5
Humanity’s Last Exam ist von hohem wissenschaftlichem Niveau, das wohl kaum ein Nutzer jemals erreicht.
Mein vorläufiges Urteil
Ich vergleiche die Modell nicht ständig bzgl. Details, aber mein Bauchgefühl ist, dass es für den normalen User keinen stark spürbaren Unterschied ggü. ChatGPT 5.1 geben wird. Aber ich teste auch noch – und die Daten aus unabhängigen Tests werden mit der Zeit aussagekräftiger.
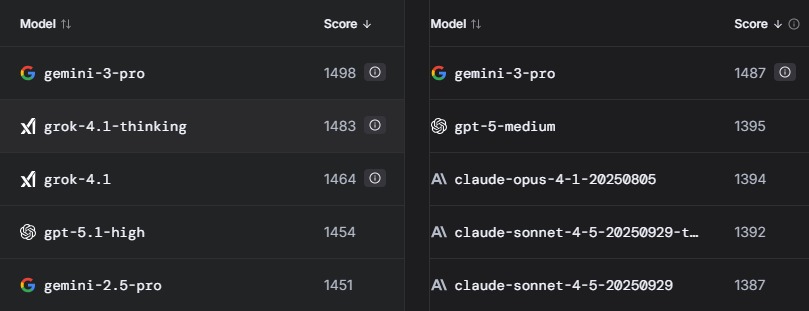
Bei der LLM Arena, einem Test im Netz durch Nutzer, schneidet Gemini 3 zwar deutlich besser, aber nicht um Welten besser ab: