Updates am 03.11.25:
- Ergänzung um die modellunabhängig schlechten Ergebnisse bei „Humanity’s Last Exam“.
- Empfehlung zum Einsatz von KI-Sprachmodellen.
Das große Problem mit jedem KI-Sprachmodell ist, dass es rein statistisch arbeit – es „weiß“ in Wirklichkeit wenig. KI-Sprachmodelle sind übrigens auch nur eine kleine Nische der künstlichen Intelligenz. Alle KI-Sprachmodelle nutzen lediglich statistische Wahrscheinlichkeiten, um zu antworten. Die Basis dafür ist das Wissen eines großen Teils des Internets, wodurch die Modelle sehr gut die im Fragenkontext richtigen Wörter vorhersagen kann. Die Wörter (eigentlich Silben/Token), die am wahrscheinlichsten sind, werden ausgegeben. Oft, bei Themen, die im Internet ausführlich und einheitlich beschrieben werden, klappt das sehr gut: die Relativitätstheorie hat Einstein aufgestellt. Das gibt jedes KI-Modell richtig wieder, da die allermeisten Quellen eindeutig sind. Wenn etwas nicht sicher ist, sieht das ganz anders aus. Dann zeigen sich die Grenzen der KI-Sprachmodelle.

Der Begriff „Halli Galli“ im KI-Sprachmodell
In meinem Sprachgebrauch bedeutet „Halli Galli“ so etwas wie „Lärm“, und so kam es auch zu dem Test für KI-Sprachmodelle, den ich hier beschreibe. Laut dem Duden schreibt man es übrigens korrekt Halligalli – das ist aber für diesen Artikel bzw. Test nicht wichtig.
Halligalli, Hully-Gully, das
duden.de, der Begriff wurde 2004 aufgenommen
– fröhliches, lärmendes Treiben; ausgelassene Stimmung
Als KI-Sprachmodelle noch neu waren, war ich auf einer Dienstreise morgens in meinem Hotelzimmer und war genervt vom Lärm im Gang, der für meinen Geschmack sehr früh begann. Ich schrieb meiner Frau: „Da ist leider ganz schön viel Halli Galli im Treppenhaus.“ Da KI-Sprachmodelle so neu waren, wollte ich testen, ob ChatGPT mir den Begriff erklären kann. Wie gewohnt antwortete das KI-Sprachmodell sehr selbstsicher. Als ich später diese Erklärung meiner Frau schicken wollte, machte ich der Einfachheit in der Bedienung halber die Anfrage noch einmal.
Ich war sehr überrascht, dass die zweite Antwort des gleichen KI-Sprachmodells mit der ersten Antwort sehr wenig zu tun hatte. Seither ist „Halli Galli“ mein Standardtest für KI-Modelle, um herauszufinden, wie sie mit Unsicherheiten umgehen. Leider antworten bis heute alle getesteten KI-Sprachmodelle sehr selbstsicher mit einer der Varianten, die im Internet kursieren. Ich habe leider noch kein Modell erlebt, das mir mitgeteilt hat, dass es sich in der Ausssage unsicher ist.

Warum ist das wichtig für die Nutzung?
Ich mag diesen Test sehr, weil er sehr deutlich zeigt, dass die KI-Sprachmodelle wenig „wissen“, auch wenn die Antworten immer sehr selbstbewusst präsentiert werden, als wüsste das Gegenüber genau, wovon es redet. Nach dem Erscheinen von ChatGPT 5 habe ich dieses neue „noch bessere“ KI-Sprachmodell direkt mit Halli-Galli getestet und das gewohnte Ergebnis erhalten. Ich habe die zwei Antworten aus zwei separaten Chats (keine Historie) in unterschiedliche Dokumente kopiert. Dann habe ChatGPT 5 diese Antworten vergleichen lassen:

Warum macht ein KI-Sprachmodell noch Fehler?
Es ist eine Grundlage der KI-Sprachmodelle, dass sie mit möglichst viel Daten gefüttert werden, um dann auf Basis der vorhandenen Wörter in der Frage und dem bisherigen Teil der Antwort das zu schreiben, was am wahrscheinlichsten die richtige Antwort ist.

Das sogenannte „Training“ eines KI-Sprachmodells bedeutet, dass es mit sehr, sehr vielen Daten lernt, welche Wortteile am häufigsten mit welchen anderen Wortteilen vorkommen. Die Basis sind z.B. Webseiten, Foreneinträge wie auf Reddit, Blogartikel, Bücher etc. Darauf folge das „Optimieren“ des KI-Sprachmodells. Dieser Schritt führt dazu, dass die falschen Antworten weniger werden, weil dem Modell beigebracht wird, was es nicht ausgeben sollen. Das können unerwünschte politisch problematische Antworten sein. Es kann sich aber z.B. auch um die richtige Antwort auf die Frage „Wieviele r sind im Wort Strawberry“ handeln – ein klassischer Test, um die Qualität eines KI-Sprachmodells zu testen.
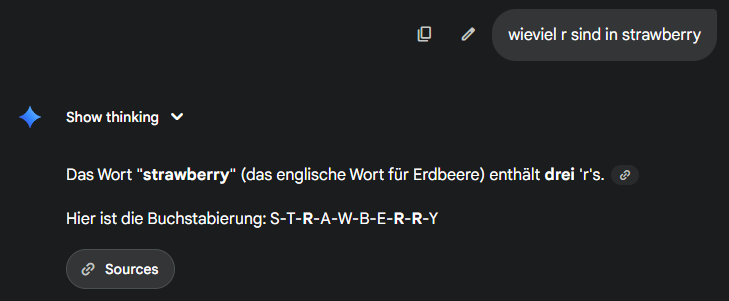
Weil es die Antwort aus einem Youtube-Video zum Thema ausgelesen hat. 😉
Insbesondere beim Training von ChatGPT sind Unmengen von Mitarbeitern in Niedriglohnländern wie Kenia damit beschäftigt worden, das zugehörige KI-Sprachmodell zu „optimieren“:

Wie die Modelle tatsächlich im Detail funktionieren ist bisher unklar – selbst das bekannte Genie Stephen Wolfram kann es nicht anders zusammen fassen, als dass es Zufall ist. Ein sehr schöner Zufall – die Tools sind in vielen Fällen sehr nützlich. Aber intelligent sind sie eben nicht, nur sehr beeindruckende Zufallsgeneratoren!

Expertenwissen? Von wegen!
Eine Initiative, die die Kompetenz von KI-Sprachmodellen misst, ist der gezielt für KI-Modelle entworfene Test „Humanity’s Last Exam“, das zugegebenerweise sehr schwierige Fragen enthält. Aktuell wird ja aber auch oft von den KI-FIrmen propagiert, dass die KI-Sprachmodelle die Kompetenz von Doktoranden erreicht haben soll. Da finde ich es schon irritierend, wenn bei den neuesten Modellen die Skala bei 45% Anteil an richtigen Antworten endet:
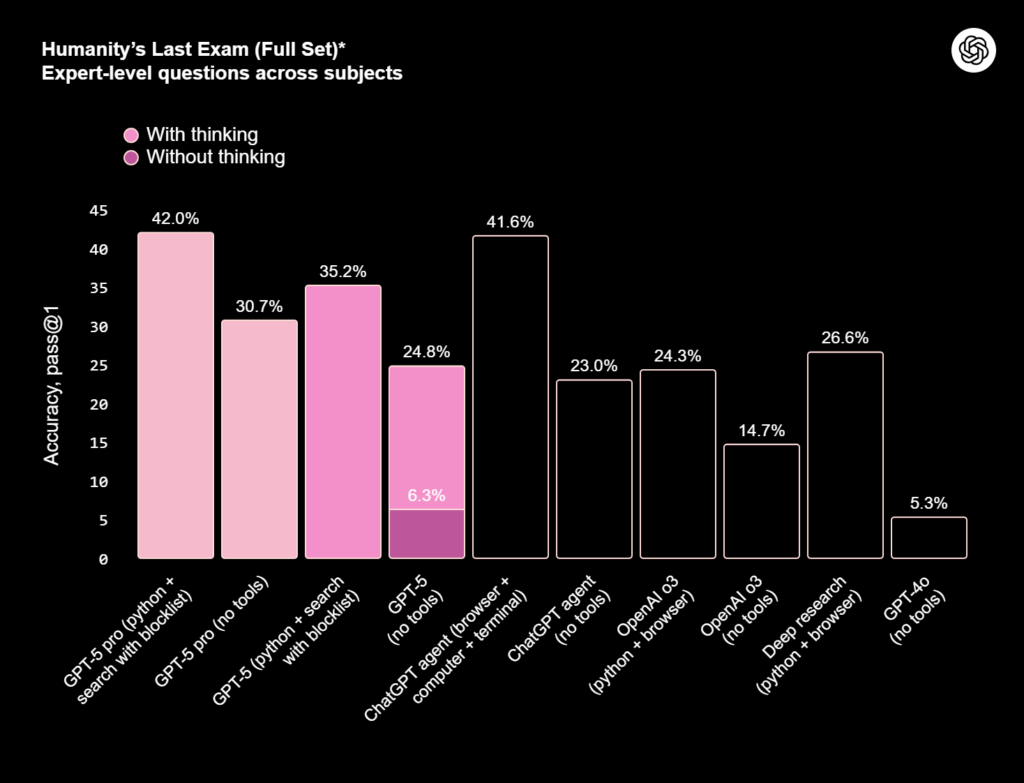
Und das ist keine Ausnahme:
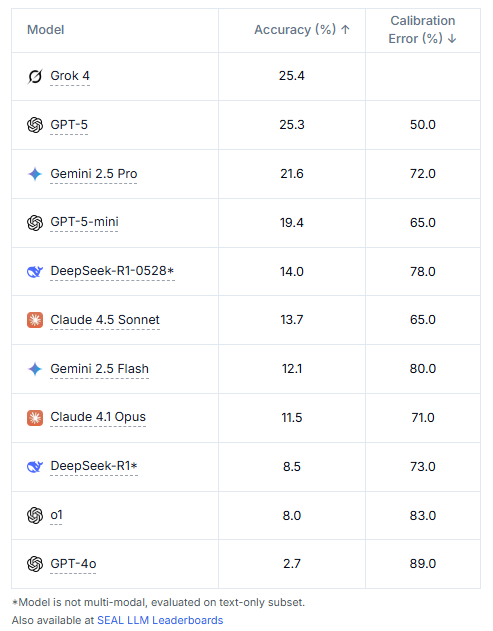
Und was kann so ein KI-Sprachmodell dann?
Ich sehe jedes KI-Sprachmodell als guten, motivierten Werkstudenten: er gibt sich echt Mühe, nutzt alle Quellen die er findet, hat aber nicht viel Erfahrung und kennt sich nur oberflächlich aus. Alles, was er als Ergebnis liefert, sollte man gegenprüfen, sofern möglich. Ein skalierter Einsatz sollte nur da erfolgen, wo auch menschlicher Fehler akzeptiert werden würde. Das ist ein gesunder, vernünftiger Umgang mit KI-Sprachmodellen!

Lust auf Austausch?
Ich tausche mich immer gerne zum Thema KI aus! Mehr Infos zu meinem Ansatz bei Traning von Mitarbeitern und Beratung findest Du auf der Homepage!
